llama.cpp
Introduction
llama.cpp is a high-performance, open-source project written in C/C++. Its primary goal is to run large language models locally on consumer-grade hardware, with a particular focus on CPUs. Originally developed by Georgi Gerganov for efficient inference of Meta's LLaMA models, it has since expanded to support a wide array of other open-source models.
Core Features:
- Pure CPU Inference: Its standout advantage is the ability to run multi-billion parameter models using only the CPU and system RAM, without requiring powerful discrete GPUs. This dramatically lowers the barrier to entry for local AI deployment.
- Extreme Performance & Quantization: The project employs highly optimized computation kernels (e.g., AVX2, AVX-512) and actively promotes model quantization. By compressing model weights from FP16 down to 4-bit or lower precision, it significantly reduces memory footprint and boosts inference speed with minimal loss in quality.
- Lightweight & Cross-Platform: The project has minimal dependencies and compiles into a compact executable. It supports multiple operating systems including Windows, Linux, and macOS, and can even run on embedded devices like Raspberry Pi and smartphones.
- Rich Ecosystem & Interfaces: Beyond basic command-line interaction, it provides:
- An OpenAI-compatible HTTP API server for easy integration with other applications.
- Support for Web UI and GUI clients, offering user-friendly chat interfaces.
- Integration with AI application frameworks like LangChain.
- Open Model Format: It pioneered and popularized its own model file format, GGUF. The GGUF format is optimized for llama.cpp's inference engine, bundling model architecture, weights, tokenizer, and quantization information into a single, easy-to-distribute and load file.
Typical Use Cases:
- Running a local chatbot assistant on a GPU-less personal computer (laptop, desktop).
- Offline document processing, code completion, or creative writing in privacy-sensitive environments.
- Providing developers with a lightweight, efficient backend for integrating AI features into their applications.
- Experimenting with and researching the latest open-source LLMs without expensive cloud computing resources.
Significance: llama.cpp is a landstone in the democratization of large language models. By breaking the dependency on specialized hardware for running LLMs, it empowers anyone with a standard computer to experience and control powerful AI locally. It has profoundly accelerated the adoption and innovation of open-source AI at the edge.
Generated by AI
Image
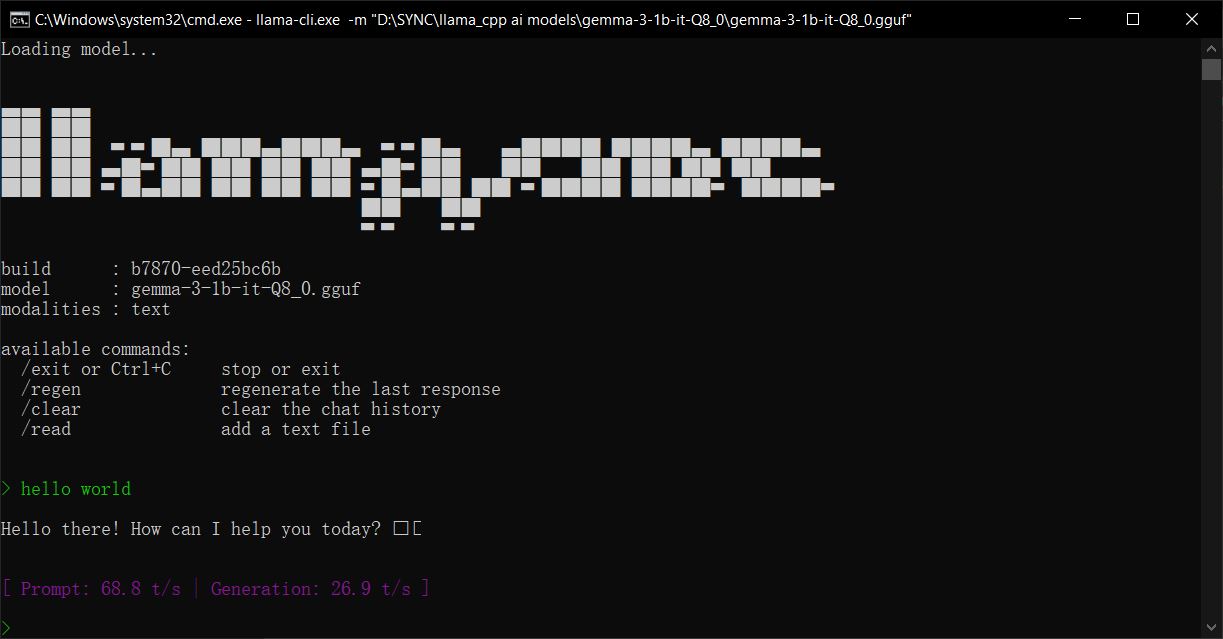
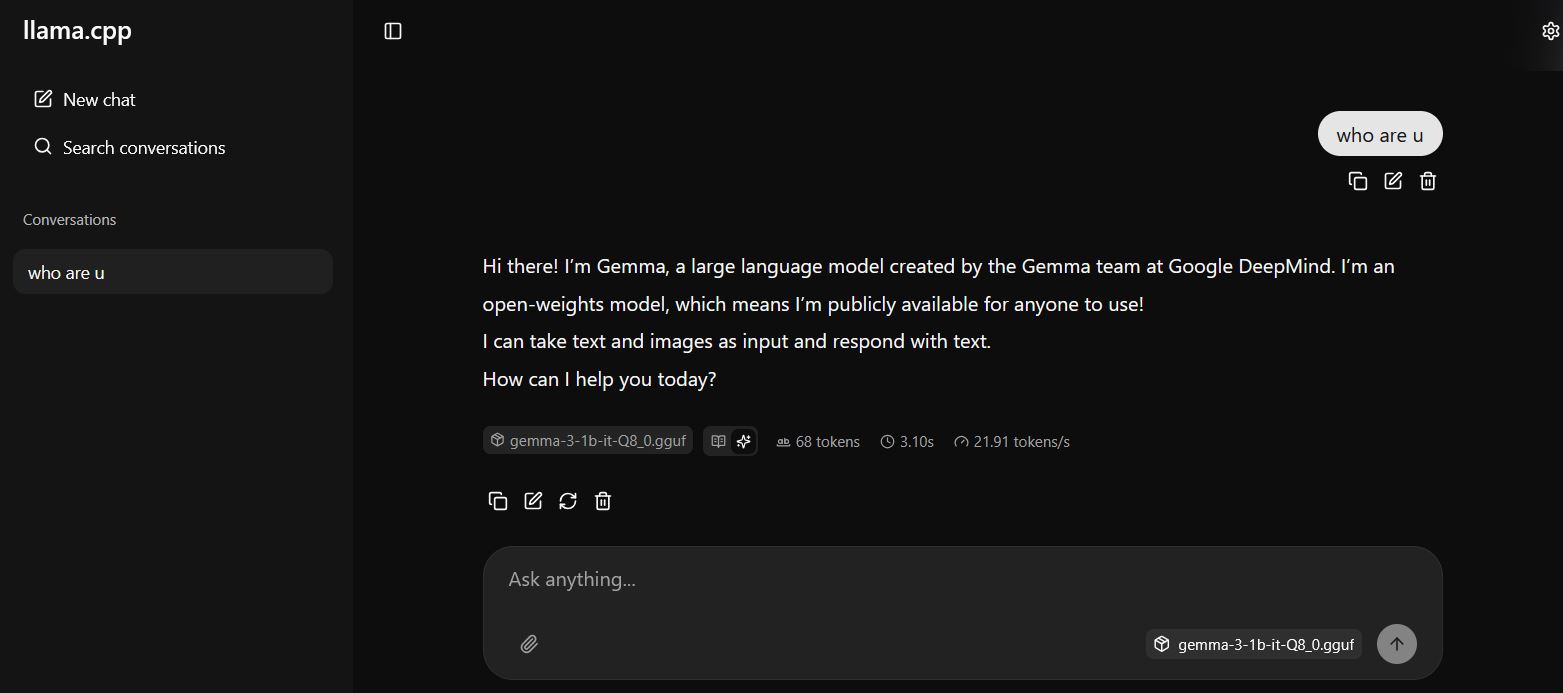
Get
Available on github:https://github.com/ggml-org/llama.cpp
Direct Download:
llama.cpp:65d19c72-5d3b-4c4f-a44a-ad717c4d20d4
some models:0a27079f-a53c-46f5-b149-75cfb09303a8
Having trouble downloading?
If you encounter any issues during the download process, refer to the following solutions:
Link invalid or incorrect How to download the ed2k link How to download the magnet link How to download the .torrent file Other problemsNote
You need to install the latest version of the VC runtime in order to run llama.cpp. You can download it here:https://learn.microsoft.com/en-us/cpp/windows/latest-supported-vc-redist?view=msvc-170#latest-supported-redistributable-version